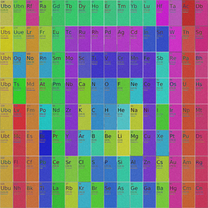
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
from __future__ import annotations
import argparse
import math
import os
import sys
from dataclasses import dataclass
from pathlib import Path
from typing import Dict, List, Tuple, Optional
import numpy as np
from PIL import Image, ImageDraw, ImageFont
import colorsys
USE_NUMBA = False
try:
from numba import njit # type: ignore
USE_NUMBA = True
except Exception:
USE_NUMBA = False
WIDTH = 4096
HEIGHT = 4096
TOTAL_COLORS = WIDTH * HEIGHT # 16,777,216
ELEMENT_COUNT = 128
GRID_COLS = 16
GRID_ROWS = 8
CELL_W = WIDTH // GRID_COLS # 256
CELL_H = HEIGHT // GRID_ROWS # 512
TEXT_MARGIN = 12
LINE_GAP = 10
AA_SCALE_DEFAULT = 2
# Thicker borders
BORDER_THICK_DEFAULT = 4 # px
# Bin quantization
BIN_SHIFT = 3
BINS_PER_CH = 256 >> BIN_SHIFT # 32
NBINS = BINS_PER_CH * BINS_PER_CH * BINS_PER_CH # 32768
ELEMENT_SYMBOLS = [
"H", "He", "Li", "Be", "B", "C", "N", "O", "F", "Ne",
"Na", "Mg", "Al", "Si", "P", "S", "Cl", "Ar", "K", "Ca",
"Sc", "Ti", "V", "Cr", "Mn", "Fe", "Co", "Ni", "Cu", "Zn",
"Ga", "Ge", "As", "Se", "Br", "Kr", "Rb", "Sr", "Y", "Zr",
"Nb", "Mo", "Tc", "Ru", "Rh", "Pd", "Ag", "Cd", "In", "Sn",
"Sb", "Te", "I", "Xe", "Cs", "Ba", "La", "Ce", "Pr", "Nd",
"Pm", "Sm", "Eu", "Gd", "Tb", "Dy", "Ho", "Er", "Tm", "Yb",
"Lu", "Hf", "Ta", "W", "Re", "Os", "Ir", "Pt", "Au", "Hg",
"Tl", "Pb", "Bi", "Po", "At", "Rn", "Fr", "Ra", "Ac", "Th",
"Pa", "U", "Np", "Pu", "Am", "Cm", "Bk", "Cf", "Es", "Fm",
"Md", "No", "Lr", "Rf", "Db", "Sg", "Bh", "Hs", "Mt", "Ds",
"Rg", "Cn", "Nh", "Fl", "Mc", "Lv", "Ts", "Og"
]
ELEMENT_NAMES = [
"Hydrogen", "Helium", "Lithium", "Beryllium", "Boron", "Carbon", "Nitrogen", "Oxygen", "Fluorine", "Neon",
"Sodium", "Magnesium", "Aluminium", "Silicon", "Phosphorus", "Sulfur", "Chlorine", "Argon", "Potassium", "Calcium",
"Scandium", "Titanium", "Vanadium", "Chromium", "Manganese", "Iron", "Cobalt", "Nickel", "Copper", "Zinc",
"Gallium", "Germanium", "Arsenic", "Selenium", "Bromine", "Krypton", "Rubidium", "Strontium", "Yttrium", "Zirconium",
"Niobium", "Molybdenum", "Technetium", "Ruthenium", "Rhodium", "Palladium", "Silver", "Cadmium", "Indium", "Tin",
"Antimony", "Tellurium", "Iodine", "Xenon", "Caesium", "Barium", "Lanthanum", "Cerium", "Praseodymium", "Neodymium",
"Promethium", "Samarium", "Europium", "Gadolinium", "Terbium", "Dysprosium", "Holmium", "Erbium", "Thulium", "Ytterbium",
"Lutetium", "Hafnium", "Tantalum", "Tungsten", "Rhenium", "Osmium", "Iridium", "Platinum", "Gold", "Mercury",
"Thallium", "Lead", "Bismuth", "Polonium", "Astatine", "Radon", "Francium", "Radium", "Actinium", "Thorium",
"Protactinium", "Uranium", "Neptunium", "Plutonium", "Americium", "Curium", "Berkelium", "Californium", "Einsteinium", "Fermium",
"Mendelevium", "Nobelium", "Lawrencium", "Rutherfordium", "Dubnium", "Seaborgium", "Bohrium", "Hassium", "Meitnerium", "Darmstadtium",
"Roentgenium", "Copernicium", "Nihonium", "Flerovium", "Moscovium", "Livermorium", "Tennessine", "Oganesson"
]
def generate_symbol(n: int) -> str:
if n <= 118:
return ELEMENT_SYMBOLS[n - 1]
digit_to_letter = ['n', 'u', 'b', 't', 'q', 'p', 'h', 's', 'o', 'e']
return ''.join(digit_to_letter[int(d)] for d in str(n)).capitalize()[:3]
def generate_name(n: int) -> str:
if n <= 118:
return ELEMENT_NAMES[n - 1]
roots = ['nil', 'un', 'bi', 'tri', 'quad', 'pent', 'hex', 'sept', 'oct', 'enn']
digits = [int(d) for d in str(n)]
parts = [roots[d] for d in digits]
if parts[-1] in ('bi', 'tri'):
parts[-1] = parts[-1][:-1]
for i in range(len(parts) - 1):
if parts[i] == 'enn' and parts[i + 1] == 'nil':
parts[i] = 'en'
return ''.join(parts).capitalize() + "ium"
def generate_weight(n: int) -> str:
return f"[{n:.1f}]"
def classify_element(n: int) -> str:
if n == 1: return "nonmetal"
if n in [2,10,18,36,54,86,118]: return "noble_gas"
if n in [5,14,32,33,51,52,84]: return "metalloid"
if n in [9,17,35,53,85,117]: return "halogen"
if n in [6,7,8,15,16,34]: return "nonmetal"
if n in [3,11,19,37,55,87,119]: return "alkali"
if n in [4,12,20,38,56,88,120]: return "alkaline"
if 57 <= n <= 71: return "lanthanide"
if 89 <= n <= 103: return "actinide"
if 104 <= n <= 112 or (21 <= n <= 30) or (39 <= n <= 48) or (72 <= n <= 80): return "transition"
if (13 <= n <= 16) or (31 <= n <= 34) or (49 <= n <= 52) or (81 <= n <= 84): return "post_transition"
if 121 <= n <= 138: return "actinide"
return "unknown"
def generate_spiral_grid(cols: int, rows: int) -> List[List[int]]:
grid = [[-1] * cols for _ in range(rows)]
cx, cy = cols // 2, rows // 2
x, y = cx, cy
dx = [1, 0, -1, 0]
dy = [0, 1, 0, -1]
steps = 1
dir_idx = 0
count = 1
while count <= cols * rows:
for _ in range(2):
for _ in range(steps):
if 0 <= x < cols and 0 <= y < rows:
grid[y][x] = count
count += 1
if count > cols * rows:
return grid
x += dx[dir_idx]
y += dy[dir_idx]
dir_idx = (dir_idx + 1) % 4
steps += 1
return grid
def dilate8(mask: np.ndarray) -> np.ndarray:
p = np.pad(mask, 1, mode="constant", constant_values=False)
c = p[1:-1, 1:-1]
n = p[:-2, 1:-1]
s = p[2:, 1:-1]
w = p[1:-1, :-2]
e = p[1:-1, 2:]
nw = p[:-2, :-2]
ne = p[:-2, 2:]
sw = p[2:, :-2]
se = p[2:, 2:]
return c | n | s | w | e | nw | ne | sw | se
def _candidate_font_dirs() -> List[Path]:
dirs: List[Path] = []
windir = os.environ.get("WINDIR", r"C:\Windows")
dirs.append(Path(windir) / "Fonts")
dirs += [Path("/Library/Fonts"), Path.home() / "Library" / "Fonts"]
dirs += [Path("/usr/share/fonts"), Path("/usr/local/share/fonts"), Path.home() / ".fonts"]
return [d for d in dirs if d.exists()]
def find_font_file(name_substr: str, prefer_bold: bool) -> Optional[str]:
name_substr_l = name_substr.lower()
exts = (".ttf", ".otf", ".ttc")
best: Optional[Path] = None
best_score = -1
for d in _candidate_font_dirs():
try:
if sys.platform.startswith("win"):
paths = [d / p for p in os.listdir(d)]
else:
paths = list(d.glob("*")) + list(d.glob("*/*")) + list(d.glob("*/*/*"))
except Exception:
continue
for p in paths:
if not p.is_file() or p.suffix.lower() not in exts:
continue
fn = p.name.lower()
if name_substr_l not in fn:
continue
score = 0
if prefer_bold:
if "bold" in fn: score += 50
if "semibold" in fn or "demi" in fn: score += 30
else:
if "regular" in fn or "book" in fn: score += 20
if "bold" in fn: score -= 10
if "myriad" in fn: score += 10
if "pro" in fn: score += 5
if score > best_score:
best_score = score
best = p
return str(best) if best else None
@dataclass
class Fonts:
small: ImageFont.FreeTypeFont
regular: ImageFont.FreeTypeFont
bold: ImageFont.FreeTypeFont
def load_fonts(cell_h: int, font_regular_path: Optional[str], font_bold_path: Optional[str], aa_scale: int) -> Fonts:
fs_symbol = max(28, int(cell_h * 0.20)) * aa_scale
fs_reg = max(18, int(cell_h * 0.08)) * aa_scale
fs_small = max(14, int(cell_h * 0.05)) * aa_scale
reg_path = font_regular_path or find_font_file("Myriad", prefer_bold=False) or "DejaVuSans.ttf"
bold_path = font_bold_path or find_font_file("Myriad", prefer_bold=True) or reg_path
small = ImageFont.truetype(reg_path, fs_small)
regular = ImageFont.truetype(reg_path, fs_reg)
bold = ImageFont.truetype(bold_path, fs_symbol)
return Fonts(small=small, regular=regular, bold=bold)
def render_text_mask(cell_w: int, cell_h: int, n: int, fonts: Fonts, aa_scale: int) -> np.ndarray:
Wb = cell_w * aa_scale
Hb = cell_h * aa_scale
mask_big = Image.new("L", (Wb, Hb), 0)
draw = ImageDraw.Draw(mask_big)
lines = [
(str(n), fonts.regular),
(generate_symbol(n), fonts.bold),
(generate_weight(n), fonts.regular),
(generate_name(n), fonts.small),
]
x = TEXT_MARGIN * aa_scale
y = TEXT_MARGIN * aa_scale
for text, font in lines:
draw.text((x, y), text, font=font, fill=255)
y += int(font.size + (LINE_GAP * aa_scale))
mask_small = mask_big.resize((cell_w, cell_h), resample=Image.BOX)
arr = np.asarray(mask_small, dtype=np.uint8)
return arr >= 96
def compute_masks_for_cell(n: int, fonts: Fonts, aa_scale: int, border_thick: int) -> Tuple[np.ndarray, np.ndarray, np.ndarray, np.ndarray]:
label = render_text_mask(CELL_W, CELL_H, n, fonts, aa_scale)
t = max(1, int(border_thick))
border = np.zeros((CELL_H, CELL_W), dtype=bool)
border[:t, :] = True
border[-t:, :] = True
border[:, :t] = True
border[:, -t:] = True
label = label & (~border)
outline = dilate8(label) & (~label) & (~border)
fill = ~(label | outline | border)
return label, outline, border, fill
def bin_of_color_ids(ids: np.ndarray) -> np.ndarray:
r = (ids >> 16) & 0xFF
g = (ids >> 8) & 0xFF
b = ids & 0xFF
br = r >> BIN_SHIFT
bg = g >> BIN_SHIFT
bb = b >> BIN_SHIFT
return (br << 10) | (bg << 5) | bb
if USE_NUMBA:
@njit
def _bin_of_color_numba(c: np.uint32) -> np.int32:
r = (c >> 16) & 0xFF
g = (c >> 8) & 0xFF
b = c & 0xFF
br = r >> BIN_SHIFT
bg = g >> BIN_SHIFT
bb = b >> BIN_SHIFT
return (br << 10) | (bg << 5) | bb
@njit
def build_bin_pool_from_perm_numba(perm: np.ndarray) -> Tuple[np.ndarray, np.ndarray, np.ndarray]:
counts = np.zeros(NBINS, dtype=np.int32)
n = perm.shape[0]
for i in range(n):
counts[_bin_of_color_numba(perm[i])] += 1
start = np.empty(NBINS, dtype=np.int32)
end = np.empty(NBINS, dtype=np.int32)
s = 0
for b in range(NBINS):
start[b] = s
s += counts[b]
end[b] = s
nxt = start.copy()
grouped = np.empty(n, dtype=np.uint32)
for i in range(n):
c = perm[i]
b = _bin_of_color_numba(c)
j = nxt[b]
grouped[j] = c
nxt[b] = j + 1
return grouped, start, end
def build_bin_pool_from_perm(perm: np.ndarray) -> Tuple[np.ndarray, np.ndarray, np.ndarray]:
if USE_NUMBA:
return build_bin_pool_from_perm_numba(perm)
bins = bin_of_color_ids(perm).astype(np.int32)
counts = np.bincount(bins, minlength=NBINS).astype(np.int32)
start = np.zeros(NBINS, dtype=np.int32)
start[1:] = np.cumsum(counts[:-1])
end = start + counts
order = np.argsort(bins, kind="stable")
grouped = perm[order]
return grouped, start, end
@dataclass
class BinAllocator:
grouped: np.ndarray
cur: np.ndarray
end: np.ndarray
class BinStream:
def __init__(self, alloc: BinAllocator, bins_order: np.ndarray):
self.a = alloc
self.bins = bins_order.astype(np.int32, copy=False)
self.i = 0
def take(self, k: int) -> np.ndarray:
out = np.empty(k, dtype=np.uint32)
o = 0
while o < k:
if self.i >= self.bins.shape[0]:
raise RuntimeError("BinStream exhausted bins_order.")
b = int(self.bins[self.i])
avail = int(self.a.end[b] - self.a.cur[b])
if avail <= 0:
self.i += 1
continue
n = min(avail, k - o)
s = int(self.a.cur[b]); e = s + n
out[o:o+n] = self.a.grouped[s:e]
self.a.cur[b] = e
o += n
if self.a.cur[b] >= self.a.end[b]:
self.i += 1
return out
@dataclass
class CellInfo:
n: int
col: int
row: int
series: str
def build_cells() -> List[CellInfo]:
spiral = generate_spiral_grid(GRID_COLS, GRID_ROWS)
pos_by_element: Dict[int, Tuple[int, int]] = {}
for y in range(GRID_ROWS):
for x in range(GRID_COLS):
n = spiral[y][x]
if 1 <= n <= ELEMENT_COUNT:
pos_by_element[n] = (x, y)
cells: List[CellInfo] = []
for n in range(1, ELEMENT_COUNT + 1):
col, row = pos_by_element[n]
cells.append(CellInfo(n=n, col=col, row=row, series=classify_element(n)))
return cells
def cell_bounds(col: int, row: int) -> Tuple[int, int, int, int]:
x0 = col * CELL_W
y0 = row * CELL_H
return x0, y0, x0 + CELL_W, y0 + CELL_H
def main():
ap = argparse.ArgumentParser()
ap.add_argument("--out", default="periodic_table_allrgb_128_spiral.png")
ap.add_argument("--seed", type=int, default=1)
ap.add_argument("--aa", type=int, default=AA_SCALE_DEFAULT)
ap.add_argument("--border", type=int, default=BORDER_THICK_DEFAULT, help="Border thickness in pixels (default: 4)")
ap.add_argument("--font-regular", default=None)
ap.add_argument("--font-bold", default=None)
args = ap.parse_args()
aa_scale = max(1, int(args.aa))
border_thick = max(1, int(args.border))
cells = build_cells()
fonts = load_fonts(CELL_H, args.font_regular, args.font_bold, aa_scale)
# Count masks + series demand
total_label = total_outline = total_border = 0
fill_by_series: Dict[str, int] = {}
for c in cells:
label, outline, border, fill = compute_masks_for_cell(c.n, fonts, aa_scale, border_thick)
total_label += int(label.sum())
total_outline += int(outline.sum())
total_border += int(border.sum())
fill_by_series[c.series] = fill_by_series.get(c.series, 0) + int(fill.sum())
if total_label + total_outline + total_border + sum(fill_by_series.values()) != TOTAL_COLORS:
raise RuntimeError("Mask accounting mismatch.")
# Bin metrics
def precompute_bin_metrics():
hue = np.zeros(NBINS, dtype=np.float32)
sat = np.zeros(NBINS, dtype=np.float32)
val = np.zeros(NBINS, dtype=np.float32)
for b in range(NBINS):
br = (b >> 10) & 31
bg = (b >> 5) & 31
bb = b & 31
rc = (br << BIN_SHIFT) + (1 << (BIN_SHIFT - 1))
gc = (bg << BIN_SHIFT) + (1 << (BIN_SHIFT - 1))
bc = (bb << BIN_SHIFT) + (1 << (BIN_SHIFT - 1))
h, s, v = colorsys.rgb_to_hsv(rc / 255.0, gc / 255.0, bc / 255.0)
hue[b] = h; sat[b] = s; val[b] = v
return hue, sat, val
hue, sat, val = precompute_bin_metrics()
bins = np.arange(NBINS, dtype=np.int32)
# Dark/light/border bin orders (unchanged)
dark_bins = bins[np.lexsort((-(sat.astype(np.float64)), val.astype(np.float64)))]
light_bins = bins[np.lexsort((sat.astype(np.float64), -val.astype(np.float64)))]
border_bins = bins[np.lexsort((-val.astype(np.float64), np.abs(val.astype(np.float64) - 0.5), sat.astype(np.float64)))]
# FILL bin order: push low-saturation (gray-ish) bins to the end
# Primary: is_gray (0 first, 1 last), then hue, then prefer higher sat/val.
S_GRAY = 0.20
is_gray = (sat < S_GRAY).astype(np.int32)
fill_bins = bins[np.lexsort((
-val.astype(np.float64),
-sat.astype(np.float64),
hue.astype(np.float64),
is_gray.astype(np.float64), # primary (last key): colorful first, grays last
))]
rng = np.random.default_rng(args.seed)
perm = rng.permutation(TOTAL_COLORS).astype(np.uint32)
grouped, start, end = build_bin_pool_from_perm(perm)
alloc = BinAllocator(grouped=grouped, cur=start.copy(), end=end)
label_stream = BinStream(alloc, dark_bins)
outline_stream = BinStream(alloc, light_bins)
border_stream = BinStream(alloc, border_bins)
fill_stream = BinStream(alloc, fill_bins)
label_colors = label_stream.take(total_label)
outline_colors = outline_stream.take(total_outline)
border_colors = border_stream.take(total_border)
series_order = sorted(fill_by_series.keys())
series_fill_colors: Dict[str, np.ndarray] = {}
for s in series_order:
series_fill_colors[s] = fill_stream.take(fill_by_series[s])
img_ids = np.zeros((HEIGHT, WIDTH), dtype=np.uint32)
idx_label = idx_outline = idx_border = 0
idx_fill = {s: 0 for s in series_order}
for c in cells:
x0, y0, x1, y1 = cell_bounds(c.col, c.row)
cell = img_ids[y0:y1, x0:x1] # view
label, outline, border, fill = compute_masks_for_cell(c.n, fonts, aa_scale, border_thick)
# Fill
fill_idx = np.flatnonzero(fill)
kf = fill_idx.size
if kf:
chunk = series_fill_colors[c.series][idx_fill[c.series]: idx_fill[c.series] + kf]
idx_fill[c.series] += kf
rr = np.random.default_rng((args.seed * 1000003 + c.n) & 0xFFFFFFFF)
rr.shuffle(fill_idx)
yy = fill_idx // CELL_W
xx = fill_idx % CELL_W
cell[yy, xx] = chunk
# Border (now thicker)
border_idx = np.flatnonzero(border)
kb = border_idx.size
if kb:
yy = border_idx // CELL_W
xx = border_idx % CELL_W
cell[yy, xx] = border_colors[idx_border: idx_border + kb]
idx_border += kb
# Outline
outline_idx = np.flatnonzero(outline)
ko = outline_idx.size
if ko:
yy = outline_idx // CELL_W
xx = outline_idx % CELL_W
cell[yy, xx] = outline_colors[idx_outline: idx_outline + ko]
idx_outline += ko
# Label
label_idx = np.flatnonzero(label)
kl = label_idx.size
if kl:
yy = label_idx // CELL_W
xx = label_idx % CELL_W
cell[yy, xx] = label_colors[idx_label: idx_label + kl]
idx_label += kl
# Convert packed ids -> RGB
rgb = np.empty((HEIGHT, WIDTH, 3), dtype=np.uint8)
rgb[..., 0] = ((img_ids >> 16) & 0xFF).astype(np.uint8)
rgb[..., 1] = ((img_ids >> 8) & 0xFF).astype(np.uint8)
rgb[..., 2] = (img_ids & 0xFF).astype(np.uint8)
Image.fromarray(rgb, "RGB").save(args.out)
print(f"✅ Saved: {args.out}")
if __name__ == "__main__":
main()